| SUSE LINUX Enterprise Server – Installation and Administration Chapter 19. High Availability under Linux / 19.2. A Sample Minimum Scenario | ||||
|---|---|---|---|---|
 | Chapter 19. High Availability under Linux | 19.3. Components of a High Availability Solution |  | |
| SUSE LINUX Enterprise Server – Installation and Administration Chapter 19. High Availability under Linux / 19.2. A Sample Minimum Scenario | ||||
|---|---|---|---|---|
| Chapter 19. High Availability under Linux | 19.3. Components of a High Availability Solution | | |
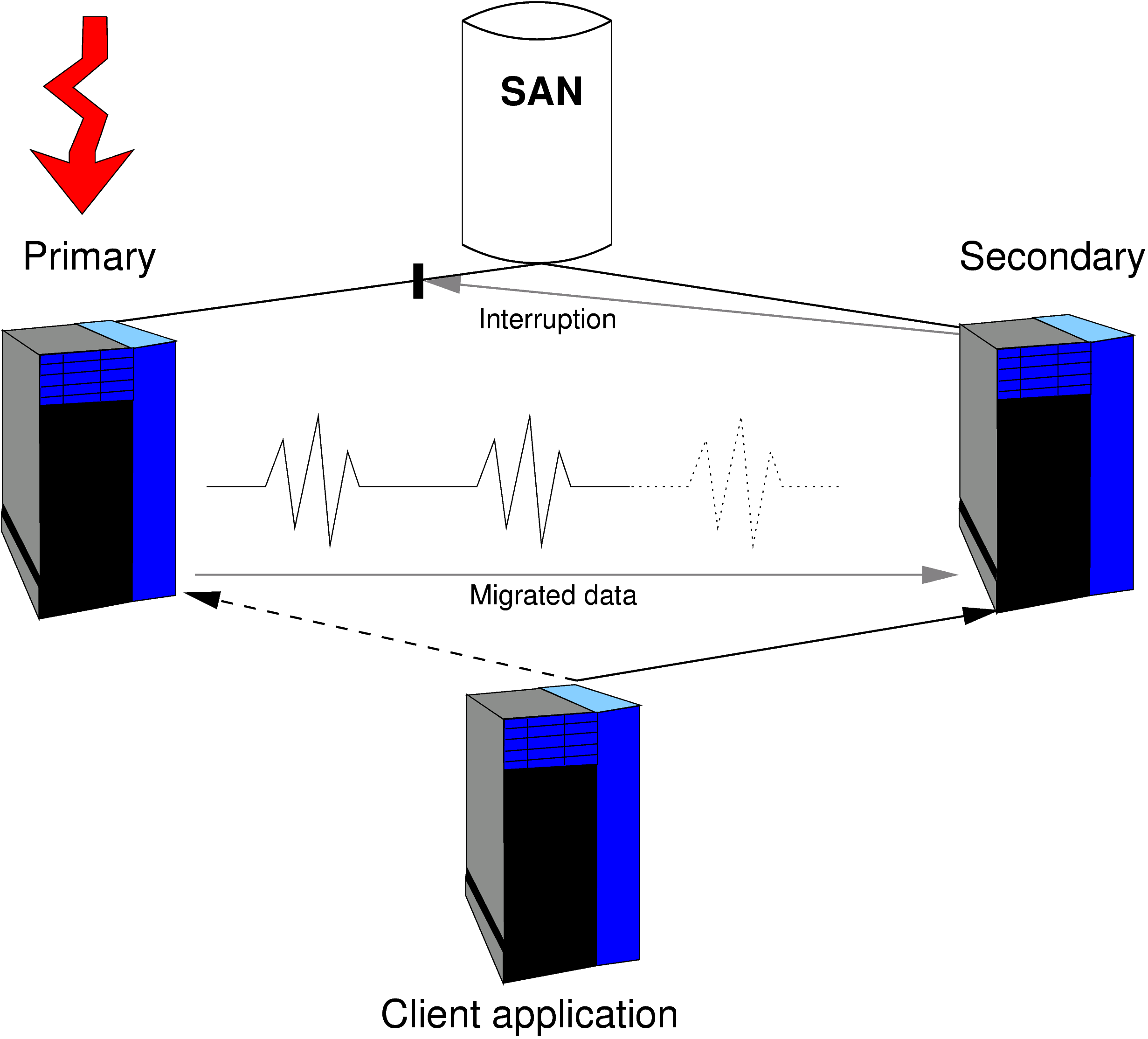
The procedures within a two-node cluster when one node fails and the various types of standby systems that can take over as necessary are outlined below (see Figure 19.1. “A Simple High Availability Cluster”).
The two servers (primary and backup) are both connected to a SAN (storage area network). Depending on the mode, this is only accessed by the active node. The servers communicate with each other in such a way that they regularly emit a “sign of life” (heartbeat). The communication channels (or heartbeat links) are also laid out in a redundant way, so independent channels can be used by means of a variety of network cards and cable channels. If one of the links fails, its backups continue to report correctly that the relevant server is still “alive”. If there is no sign of life from the main system, the standby system is activated, so it takes over the services of the failed partner and removes it from the network completely (STONITH).